
Beyond the Context Window: Elevating LLMs with RAG
How companies actually use LLMs.

Actionable Summary
Ground AI In Reality: Overcome the limitations of Large Language Models (LLMs) by integrating Retrieval-Augmented Generation (RAG) for real-time, accurate responses.
Leverage Vectors and Embeddings: Understand how transforming data into vectors enables semantic search and precise information retrieval.
Implement RAG Step-by-Step: Data Collection, Embedding Data, Process User Queries, Semantic Retrieval, Augmentation and Generation.
Understand Re-Ranking: Prioritize the most relevant information by re-ordering retrieved documents before they reach the LLM.
Platform Shift
Remember in 2009 when the cloud was just that fluffy thing in the sky? Then, almost overnight, cloud computing took off and gave birth to tech legends like Salesforce, Nutanix, and Netflix—companies that didn't just ride the wave; they made the wave. Fast forward to today, and we're on the brink of another seismic shift. Generative AI isn't just the next big thing; it might be the most exciting technological development of our lifetime (Sam Altman, Bill Gates).

Large Language Models like OpenAI’s GPT-4 burst onto the scene, dazzling us with their ability to generate human-like text, draft emails, write code, and even whip up poetry on the fly. It's like having Shakespeare, Einstein, and a really chatty friend all rolled into one. But as incredible as these models are, they're not without their quirks. They can "hallucinate" (making up stuff that sounds legit but isn't), they're stuck in a time warp with knowledge only up to their last training date, and they don't know a thing about your company's proprietary data or that niche industry lingo.
Enter Retrieval-Augmented Generation (RAG)—the dynamic duo partner to our superhero LLMs. Think of RAG as giving your AI a direct line to the latest, most relevant information it needs, exactly when it needs it. It's like upgrading your AI from a well-read scholar to a street-smart genius who knows all the insider info.
In this series of articles, we're diving deep into the modern RAG stack—the toolkit companies are using to supercharge their AI applications. We'll explore how RAG works, break down the current market players, and spotlight where the real opportunities lie for startups and enterprises. Whether you're an AI enthusiast looking to stay ahead of the curve or a business leader aiming to harness this tech revolution, we've got the insights to help you navigate this exciting frontier.
The Limitations of LLMs and the Need for RAG
Hallucinations and Unreliable Outputs
LLMs are known to generate text that is coherent and contextually relevant but not necessarily accurate. This phenomenon, known as "hallucination," poses significant challenges for applications requiring factual correctness.
As Sridhar Ramaswamy, CEO of Snowflake, aptly put it, "You have no business believing the raw output of a language model for anything. You can’t actually do any business with that because it’s ungrounded. It doesn’t understand truth from falsehood, doesn’t understand authority"
Outdated Knowledge
Most LLMs are trained on datasets that include information only up to a certain cutoff date. For instance, an LLM trained in 2021 will not have knowledge of events, developments, or data that emerged afterward.

This temporal limitation restricts the model's applicability in dynamic environments where real-time information is crucial.
Lack of Domain-Specific and Proprietary Data
LLMs are generalized models that lack access to proprietary or domain-specific data. Enterprises need AI solutions that can understand and process confidential information, internal documents, and specialized domain-specific datasets. Without access to this data, LLMs cannot fully meet the needs of enterprise applications.
For example, how can a chat support bot on a website solve customer questions without access to the company’s help and support documents?
How can a finance chatbot answer questions about the latest earning release without access to it?
Naïve Approaches and Their Limitations
Why Don’t We Just Insert All The Data Into The Context?
A common approach to mitigate the limitations of LLMs is to insert relevant data directly into the model's context window during inference. This method involves providing the model with additional information in the prompt, hoping it will use this data to generate accurate responses.
Context Insertion Failure
- Context Size Limitations: LLMs have a fixed maximum context window, typically measured in tokens (words or subwords). Exceeding this limit results in truncation or failure to process the input.

- Performance Degradation: Even within the context window, providing large amounts of data can overwhelm the model, leading to slower response times and reduced accuracy.

- Inefficiency with Large Datasets: This method is impractical for applications requiring access to vast amounts of data, as it cannot scale effectively.

Retrieval-Augmented Generation (RAG)
RAG is currently the standard method for providing LLMs with relevant context during inference. RAG combines LLMs with external retrieval systems, allowing models to access relevant information dynamically during inference. This approach enhances the model's ability to generate accurate, context-aware responses. Before we get into the RAG architecture, we need to begin with vectors.
Vectors
Imagine you have a secret code that uses numbers to represent complex things like words, images, or sounds. In the world of machine learning, these codes are called vectors. A vector is just a list of numbers, like [0.5, -1.2, 3.3], that can capture the essence of data in a form that computers can understand and manipulate.
Vector Similarity
Now, suppose you want to find out how similar two pieces of data are—say, two sentences or two images. Since they're represented as vectors, you can compare them mathematically. This is where vector similarity comes into play. By measuring the distance or angle between two vectors in a multidimensional space, you can quantify how alike they are.
Common Ways to Measure Similarity:
Cosine Similarity: Think of each vector as an arrow from the origin point. Cosine similarity measures the cosine of the angle between these two arrows. If they're pointing in the same direction, the cosine similarity is 1—they're very similar!
Euclidean Distance: This is like measuring the straight-line distance between two points on a map. Smaller distances mean the vectors (and thus the data they represent) are more similar.
Dot Product: Multiply corresponding elements of the vectors and add them up. A larger dot product suggests greater similarity.
Embeddings
So, how do we turn complex data into these handy vectors? Enter embeddings. Embeddings are techniques that transform data like text, images, or audio into vectors while preserving their meaningful properties.
How Embeddings Work:
Text Data: Models like Word2Vec or BERT convert words and sentences into vectors. Words with similar meanings end up with vectors that are close together in the vector space.
Image Data: Convolutional Neural Networks (CNNs) process images to extract features like edges or colors and represent them as vectors.
Audio Data: Sound waves can be converted into spectrograms (visual representations of audio) and then into vectors using neural networks.
Embeddings allow machines to grasp the "meaning" behind data, making it possible to perform tasks like searching, clustering, or making recommendations.
TLDR: Embeddings that are semantically similar are close in vector space.

RAG
Introduced in this seminal paper, Retrieval Augmented Generation (RAG), a clever system that combines embeddings with large language models (LLMs) to produce accurate and up-to-date responses.
It's like giving your AI assistant a memory bank that it can consult whenever it needs specific information.
RAG Steps
Let's dive into how a RAG system works, step by step:
Data Collection: Gather all the documents or pieces of information you want your system to know about—think articles, manuals, FAQs, etc.
Embedding the Data:
Use an embedding model to convert each document into a vector.
Store these vectors in a vector database, which is optimized for handling and searching vectors efficiently.
User Query:
A user asks a question or makes a request.
Convert this query into a vector using the same embedding model.
Retrieval:
Perform a semantic search in the vector database using the query vector.
Retrieve documents whose vectors are most similar to the query vector based on vector similarity measures.
Augmentation:
Feed the retrieved documents into the LLM's context window.
This provides the LLM with relevant information that it might not have been trained on.
Generation:
The LLM generates a response that combines its own knowledge with the new information.
The user gets an accurate, context-rich answer.
Re-Ranking
But here's the twist: not all retrieved documents are equally helpful. Some might be more relevant to the user's query than others. Re-ranking is the process of ordering these documents so that the most relevant ones are prioritized.
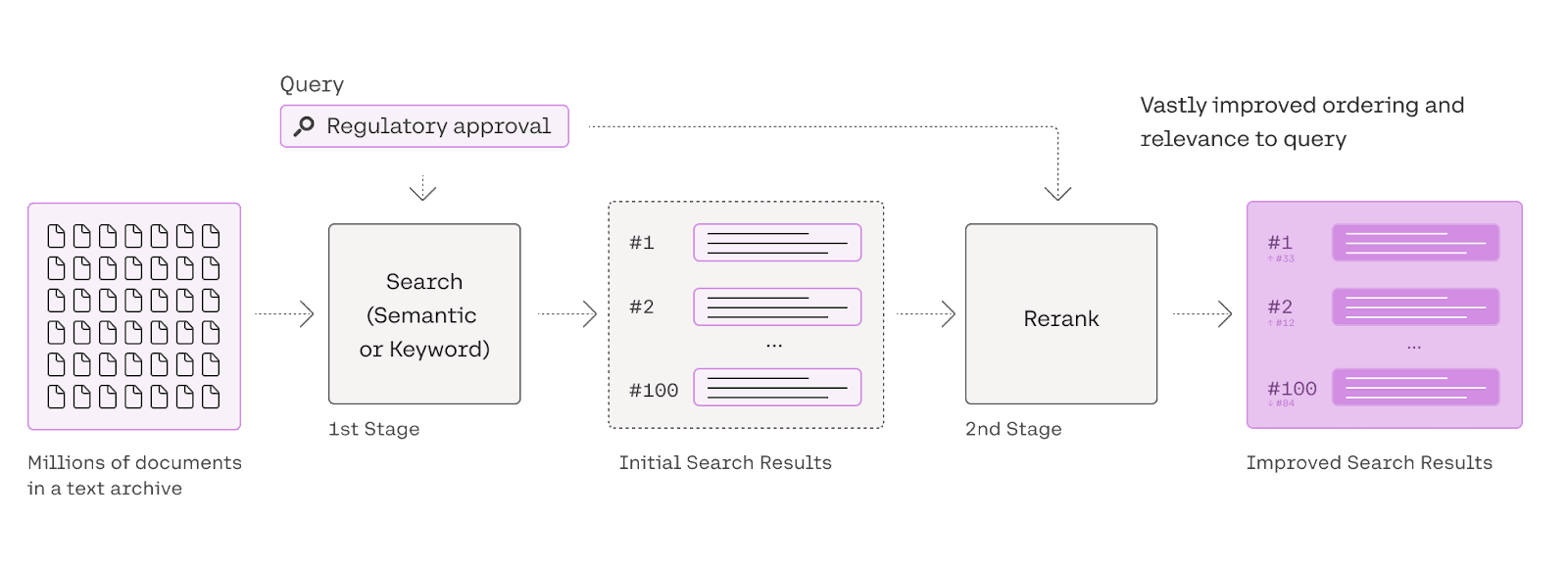
Scoring Documents with a Re-Ranking Model
Understanding Re-Ranking Models
Cross-Encoders: A common type of re-ranking model that evaluates the query and each document together.
They provide a more precise relevance score compared to initial vector similarity.
Pairwise Evaluation
Each document is paired with the query and passed through the re-ranking model.
The model outputs a relevance score for each pair.
Scores Range: Typically between 0 (not relevant) and 1 (highly relevant).
Computational Considerations
Re-ranking models are more computationally intensive than initial retrieval models.
They are applied to a smaller set of documents (e.g., top 100) to keep processing time reasonable.
Initial Retrieval vs. Re-Ranking
Initial Retrieval:
Uses bi-encoder models where the query and documents are encoded separately.
Efficient for searching large datasets but less precise.
Re-Ranking:
Uses cross-encoder models that consider the query and document together.
More computationally intensive but provides higher precision in relevance scoring.
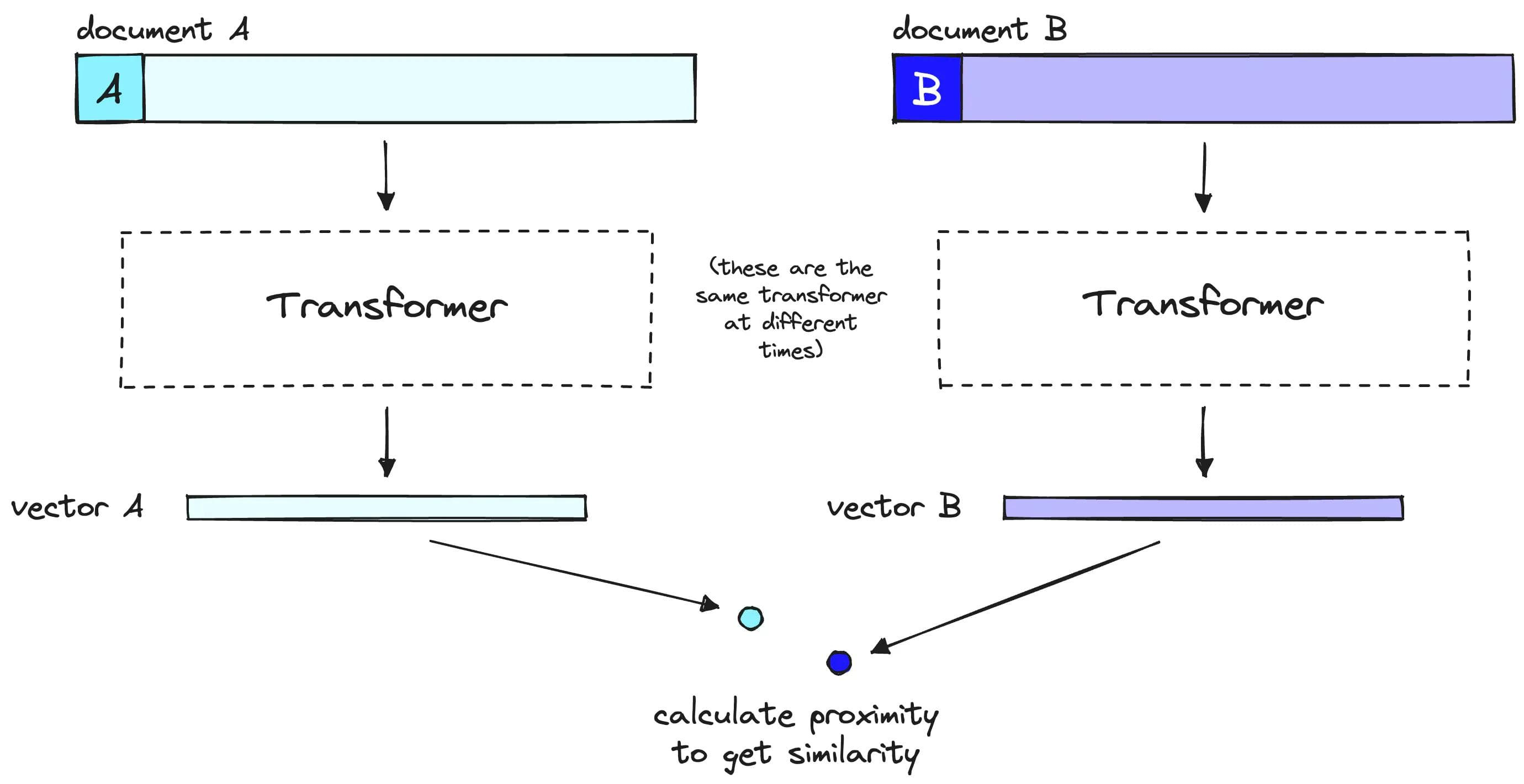
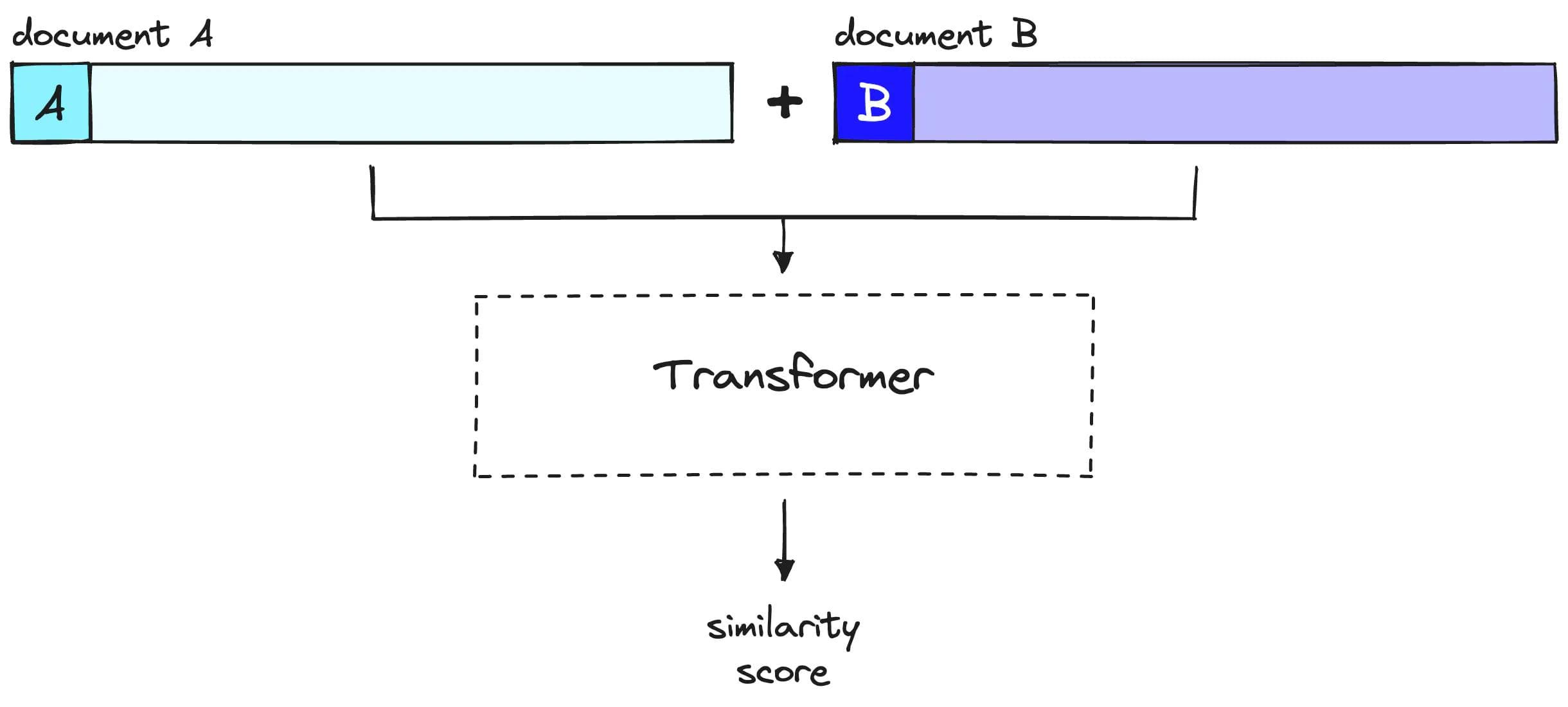
Re-Ranking Steps
Here's how re-ranking refines the RAG process:
Initial Retrieval:
Retrieve a broad set of documents (e.g., the top 20 matches) based on vector similarity.
Scoring with a Re-Ranker:
Use a re-ranking model that looks at both the query and each document together.
Assign a new, more precise relevance score to each document.
Sorting:
Re-order the documents based on these new scores, from most to least relevant.
Selecting Top Documents:
Choose the top few documents (e.g., top 3) to pass to the LLM.
This ensures the LLM focuses on the best information.
Final Generation:
The LLM uses these top-ranked documents to generate its response.
The result is a more accurate and helpful answer for the user.
RAG Is Evolving
Given its widespread adoption, RAG is a hot research area. New, state of the art methods are published weekly. I expect to see the modern RAG stack to change in the near future and continually change for the next few years.
Really helpful!