
The Modern RAG Stack
How Enterprises Are Using AI

While generative AI and fine tuning foundation models have captured headlines and imagination, RAG has quietly become the critical infrastructure powering practical AI implementations. It's telling that the past 3 Y Combinator batches have been a convention of “RAG for <INSERT INDUSTRY>”. We have seen the shift from Uber for X to ChatGPT for Y and now Agent/RAG for Z.

As an engineer who's built and deployed RAG systems, I've witnessed its evolution from a promising concept to an essential component of modern AI architecture. Fortune 500 companies aren't just experimenting with RAG – they're building their AI strategies around it. This isn't another ephemeral tech trend; RAG addresses fundamental challenges that limit foundation models, which only have general intelligence.
The core challenge is straightforward but critical: how do we transform powerful but generic language models into precise, reliable tools for specific business contexts? While ChatGPT can eloquently explain abstract concepts or generate creative content, businesses need AI systems that understand their specific products, processes, and domain expertise. This is where RAG proves invaluable.
Consider RAG as the bridge between an AI's general knowledge and your organization's specific expertise. Recently, while implementing a RAG system for a services company, their CTO crystallized the value proposition: "We don't need an AI that knows everything about everything. We need an AI that knows everything about us." This sentiment resonates across industries, from financial services to manufacturing, where domain-specific knowledge isn't just helpful – it's essential.
In manufacturing, for instance, a RAG-enabled AI system can draw upon detailed technical specifications, maintenance records, and safety protocols to provide precise, contextually relevant responses. A general foundation model might know about manufacturing principles, but only a RAG-enhanced system can tell you the maintenance history of Machine #47 on Production Line C and recommend specific actions based on your company's procedures.
In this guide to the modern RAG stack, we'll examine the core components that make these systems effective, analyze the leading solutions in each category, and explore the opportunities emerging in this rapidly evolving space. Whether you're a developer implementing RAG systems, a startup founder evaluating market opportunities, or an enterprise leader crafting your AI strategy, this guide will help you navigate the technical and strategic considerations of RAG implementation.
We'll dissect everything from embedding providers and vector databases to RAG management systems, with particular attention to critical considerations like scalability, security, and integration capabilities. And yes, we'll make vector databases sound as compelling as they actually are – which becomes evident once you understand their impact on system performance and reliability.
Beyond ChatGPT: Why Your Enterprise AI Needs RAG to Stop Hallucinating
For a refresher on how RAG works, see this post:
In the early days of enterprise generative AI adoption, companies rushed to integrate large language models into their workflows, only to face a sobering reality: these powerful models, despite their impressive capabilities, often generated responses that were confidently incorrect or dangerously outdated when it came to company-specific information. In 2023, I worked on deploying AI for a leading investment firm who deployed a fine-tuned OpenAI-powered chatbot that quoted asset pricing and news from 2019 – needless to say, the investment analysts (down stream users) immediately became skeptical of AI’s role in their research.
The fundamental limitation of foundation models lies in their training data cutoff and generic knowledge base. No matter how sophisticated the model, it can't know about your company's latest product launch, your updated compliance policies, or that crucial email from legal last week. This is where RAG becomes not just useful, but essential.

The Three Critical Problems RAG Solves
1. Knowledge Freshness
Foundation models are frozen in time, trained on historical data with a cutoff date. OpenAI's GPT-4 doesn't know about your company's Q1 2024 earnings report or your new product specifications. RAG systems continuously incorporate new information, ensuring your AI always works with current data.
2. Domain Specificity
While foundation models have broad knowledge, they lack deep expertise in your specific domain.
3. Accuracy and Accountability
Perhaps most critically, RAG systems provide something that vanilla LLMs cannot: source attribution and verification. When a RAG-enabled AI makes a claim, it can point to specific internal documents supporting that information. This isn't just about accuracy – it's about trust and compliance.
Overview of the Building Blocks of Intelligent Information Retrieval
Like any robust technology stack, RAG systems are built on several specialized components working in concert. Let's break down the three core components that make RAG systems work.
1. Embedding Providers: Your AI's Understanding of Language
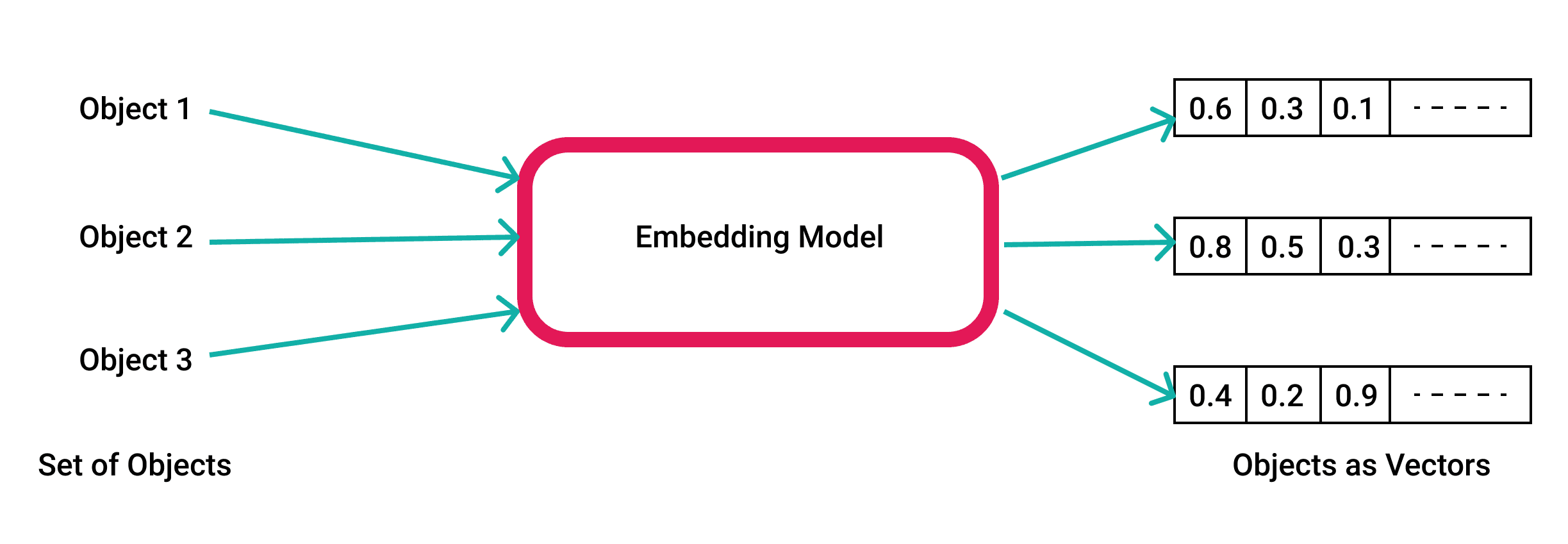
At the heart of any RAG system lies the embedding provider – the component that transforms chunks of raw information into a format that machines can understand and compare. Think of embeddings as your AI's way of understanding semantic meaning. When I explain this to non-technical stakeholders, I often use the analogy of converting words into coordinates on a map – similar concepts are placed closer together, while different concepts are placed further apart.
A deep dive on the embedding vendors and my experience is in a section below.
2. Vector Databases: The Intelligent Storage Layer
If embedding providers are the translators, vector databases are the librarians of your RAG system. They store and organize these mathematical representations of your data in a way that enables lightning-fast similarity search. But not all vector databases are created equal – especially when it comes to scaling.
A deep dive on the vector database vendors and my experience is in a section below.
3. RAG Management Systems: The Orchestra Conductor
The final piece of the puzzle is the RAG management layer – the component that orchestrates how your system retrieves, processes, and combines information. This layer handles crucial decisions like:
How to manage parsing input documents into chunks and handling updated documents
How many chunks to retrieve for each query
How to combine multiple pieces of retrieved information
When to fall back to the base model's knowledge
How to maintain context across conversation turns
Think of this component as the conductor of an orchestra – it ensures all the other components work together harmoniously.
A deep dive on RAG management systems and my experience is in a section below.
Deep Dive Into Embedding Providers
Key Vendors
Voyage AI
OpenAI
Cohere
Open Source Models:
multilingual-e5-large: Microsoftbge-reranker-v2.m3: (Re-Ranker) Beijing Academy of Artificial Intelligence (BAAI)Others (see Pinecone's model overview)
Embeddings are the unsung heroes of RAG systems. They convert your unstructured data into high-dimensional vectors that capture semantic meaning, enabling machines to understand and compare complex concepts. While this process might seem like mathematical wizardry, the choice of embedding provider can significantly impact your system's performance, scalability, and ease of integration.
Personal Experience: A Voyage with Tengyu Ma's Voyage AI
Professor Tengyu Ma was one of my Professors for Stanford’s CS229: Statistical Machine Learning. Beyond his impressive academic credentials and publications, Professor Ma has created an embedding company, Voyage AI, which has reported state of the art embedding and re-ranking results.
Last month, I built a RAG system for a pre-IPO expense management company who had to generate content based on the expenses. I decided to use Voyage’s embedding and re-ranking API. The initial results were impressive—the embeddings captured nuanced semantic relationships, and the re-ranking service noticeably improved the relevance of search results as compared to open sourced ones I used previously.
However, when scaling up for production, I encountered practical limitations. The service imposed rate limits that became bottlenecks under heavy loads. I was forced to write a custom token & request rate limiter. Additionally, the need to continuously send large volumes of data for re-ranking added latency and complexity to the system. Ideally, I would be able to share my database all at once, and then for re-ranking requests, just provide the IDs of the items to re-rank instead of having to send hundreds of raw chunks. There’s a lot of opportunity for Voyage AI to win the high-quality embedding space, but their API needs to change.
When Convenience Trumps Perfection
This experience led me to a valuable realization: sometimes, the most sophisticated solution isn't the most practical one. The performance delta between the absolute best embeddings and more readily available models is often marginal, especially when weighed against factors like scalability, cost, and integration effort.
For instance, OpenAI's text-embedding-ada-002 is a popular choice that offers a strong balance of performance and ease of use. Their rate limits are currently an order of magnitude higher than Voyage AI’s and their infrastructure is pretty robust given their backing by Microsoft.
On the open-source front, models like Microsoft's multilingual-e5-large and BAAI's bge-reranker-v2.m3 offer competitive performance without vendor lock-in. Open source embeddings integrate seamlessly with many Vector DBs, which means I do not have to think about the rate-limiting and implementation details. Using open-source models can also alleviate concerns about data privacy and compliance, as you have full control over the deployment environment.
Recommendation: Start Simple, Then Optimize
Given these considerations, I strongly recommend starting with the most convenient embedding method that fits your immediate needs. If you're using a managed vector database like Pinecone, leveraging their supported embedding models can streamline your development process. This approach allows you to focus on building the core functionality of your RAG system without getting bogged down in the complexities of managing embeddings.
Once your system is operational, you can perform A/B testing to evaluate whether switching to a different embedding provider yields significant improvements. In many cases, the gains may not justify the additional complexity and costs.
Factors to Consider When Choosing an Embedding Provider
Performance Needs: Does your application require the absolute best semantic understanding, or is "good enough" sufficient?
Scalability: Can the provider handle your expected load without bottlenecks?
Cost: How does pricing scale with usage?
Integration Effort: How smoothly does it integrate with your existing stack?
Data Privacy and Compliance: Do you need to keep all data on-premise for compliance reasons?
Thoughts On Embedding Providers
Embeddings are a critical component of your RAG system, but they're just one piece of the puzzle. In my experience, starting with a convenient and reliable embedding provider allows you to build momentum and deliver value quickly. You can then iteratively improve and optimize as you gather real-world data and user feedback.
Remember, the goal is to create a system that meets your users' needs effectively. Sometimes, that means choosing the most practical solution over the theoretically optimal one. After all, an AI system that works well today is more valuable than one that might work perfectly tomorrow.
Deep Dive Into Vector Databases
Key Vendors
Managed:
Pinecone
Azure Cosmos DB
Many more...
Open Source (OSS):
Qdrant
Weaviate
Milvus
Vespa
Chroma
LanceDB
Marqo
Many more...
Bolt-On:
Elasticsearch
MongoDB
PostgreSQL with pgvector
OpenSearch
Why Do We Need Vector Databases?
Imagine trying to store millions of unique keys in a traditional key-value store but with a twist: each key isn't a simple string but a 1,024-dimensional vector representing complex semantic information. Traditional databases aren't optimized for this kind of data. They excel at exact matches, not at finding "the closest match" among high-dimensional vectors. This is where vector databases come into play.
Vector databases are specialized storage systems designed to handle the complexity of high-dimensional vector data efficiently. They enable rapid similarity searches, which are the backbone of Retrieval-Augmented Generation (RAG) systems. Without them, searching through millions of embeddings to find relevant information would be computationally infeasible.
Axes of Comparison
When evaluating vector databases, several critical factors come into play:
Speed: How quickly can the database retrieve the top K nearest vectors?
Scale: How well does it handle millions or even billions of vectors?
Ease of Use: How straightforward is it to integrate and operate?
Compatibility: Does it support the data types and embedding models you use?
Deployment Options: Can it be self-hosted, or is it only available as a managed service?
Groups of Vector Databases
Managed Services
Pinecone
Azure Cosmos DB
Others
Managed services take care of the infrastructure, scaling, and maintenance for you. They're ideal if you want a plug-and-play solution without worrying about the underlying complexities.
Open Source (OSS)
Qdrant
Weaviate
Milvus
Vespa
Chroma
LanceDB
Marqo
Others
Open-source options offer flexibility and control, allowing you to host the database on-premises or in your cloud environment. They're essential for organizations with strict compliance requirements or those who want to avoid vendor lock-in.
Bolt-On Solutions
Elasticsearch
MongoDB
PostgreSQL with pgvector
OpenSearch
Bolt-on solutions are traditional databases or search engines that have added vector search capabilities. They can be convenient if you're already using them for other purposes but may not offer the same performance or scalability as purpose-built vector databases.
Managed Services
Pinecone
Pinecone is a fully managed, serverless vector database designed for high performance and scalability. It boasts a proprietary, innovative algorithm that departs from traditional indexing methods like Hierarchical Navigable Small World (HNSW) graphs.
Key Features:
Proprietary Algorithm: Uses hierarchical spatial partitioning with adaptive clustering, which organizes data into regions based on semantic meaning.
Serverless Architecture: Automatically scales storage and compute resources.
Integrated Embeddings: Offers hosted versions of open-source embedding and re-ranking models.
Decoupled Storage and Compute: Enhances cost savings and performance.
Pinecone argues that HNSW isn't suitable for dynamic datasets requiring frequent updates and deletions. Their architecture aims to mitigate the memory overhead and downtime associated with HNSW-based systems.
Open Source (OSS)
Qdrant
When it comes to open-source vector databases, Qdrant stands out for its focus on low latency and high throughput at scale. If you're dealing with tens of millions of vectors, Qdrant is optimized to handle that load efficiently.
Key Features:
Optimized for Large Datasets: Excels when managing over 20 million vectors.
Flexible Deployment: Offers self-hosted options, allowing you to keep data on-premises.
Proper Index Splitting and Segment Management: Handles index segmentation effectively, ensuring balanced workloads and optimal search performance.
HNSW Implementation: Utilizes HNSW for dense vector search but overcomes its limitations through intelligent design.
Weaknesses:
The company is largely based in Europe (with some sales people in the US). Given the European work-life balance, I am not sure if they will respond to e-mails at 9pm on Sunday if your core infra is down.
I had a sales call where I had budget and they promised to send over a deck. They did not follow up for over a week even after I bumped the thread. Pretty disappointing speed of execution for a high scaling AI company.
Understanding Index Splitting and Segment Management
To appreciate Qdrant's strengths, it's essential to grasp the concept of index splitting and segment management.
Why Split Indices?
As your dataset grows beyond 5 million vectors, performance can degrade if all vectors are in a single index.
Splitting the index into segments allows parallel searches across smaller subsets of data, significantly improving query times.
The Challenge of "Hot" Segments
Over time, certain segments may become "hot," receiving a disproportionate number of queries.
This imbalance can lead to uneven load distribution and slower response times.
The solution is to “split” this segment into new, smaller sub-segments.
Qdrant's Solution
Qdrant dynamically redistributes vectors across segments to maintain balanced workloads.
It ensures that no single segment becomes a bottleneck, thereby maintaining consistent performance.
While other open-source solutions claim to handle index splitting, engineers report that only Qdrant executes it properly.
Weaviate
Weaviate is another popular open-source vector database known for its rich feature set.
Key Features:
Generative Feedback Loops: Pioneered the integration of LLMs for feedback loops.
However, when it comes to handling massive datasets with complex segmentation needs, Weaviate may require additional tuning and resources.
LanceDB
LanceDB is designed for multi-modal AI applications, excelling in scenarios where you need to handle diverse data types like text, images, and audio.
Key Features:
New Columnar Data Format: Developed an alternative to Parquet that's optimized for random access and faster scans.
State-of-the-Art Vector Search: Implements efficient algorithms for quick retrieval.
Support for Nested Fields and Versioning: Offers advanced data modeling capabilities.
If your RAG system involves multi-modal data, LanceDB provides the infrastructure to manage and query this data effectively.
Bolt-On Solutions
Elasticsearch and OpenSearch
Elasticsearch is a well-known search and analytics engine that has added vector search capabilities. OpenSearch is its open-source counterpart.
Pros:
Familiarity: Many organizations already use Elasticsearch for log analytics or full-text search.
Ecosystem: Rich plugin and tooling ecosystem.
Cons:
Performance Limitations: Not optimized for high-dimensional vector search at scale.
Operational Complexity: Requires significant tuning and maintenance for vector workloads.
My Recommendations
For Open Source: Qdrant
After experimenting with various open-source vector databases, I've found Qdrant to be the most reliable when it comes to handling large-scale, dynamic datasets.
Effective Index Splitting: As previously discussed, Qdrant's ability to manage index segments efficiently sets it apart.
High Performance at Scale: Maintains low latency even as the number of vectors grows.
Flexible Deployment: Whether you need on-premises deployment for compliance or cloud-based for convenience, Qdrant has you covered.
For Multi-Modal Data: LanceDB
If your application involves more than just text—say, images, audio, or other data types—LanceDB is a compelling choice.
Optimized Data Format: Their new columnar format enhances performance for diverse data types.
Advanced Features: Supports nested fields and versioning, which can be invaluable for complex data models.
Scalable and Open Source: Offers the benefits of scalability while allowing you to retain control over your data.
Choosing the right vector database is crucial for the success of your RAG system. While managed services like Pinecone offer ease of use, they may not fit every organization's requirements, especially concerning data privacy and control. Open-source options like Qdrant and LanceDB provide the flexibility and performance needed for enterprise-grade applications.
Remember, the best choice depends on your specific needs:
Need to handle massive, dynamic datasets? Qdrant is your go-to.
Working with multi-modal data? Give LanceDB a serious look.
Prefer a managed solution that seamlessly scales to billions of vectors to reduce operational overhead? Pinecone might be the right fit.
Deep Dive into RAG Management Systems
Key Vendors
LlamaIndex
Trieve
R2R
Many more...
Simplifying RAG Deployment
Retrieval-Augmented Generation (RAG) Management Systems aim to streamline the deployment of RAG architectures, handling the intricate and often tedious details that can bog down development teams. These systems automate tasks such as data chunking, tuning of hyperparameters, and integration with vector databases and embedding models. By providing a higher-level abstraction, they allow developers to focus on building applications rather than wrestling with the underlying complexities.
Features and Functionality
Automated Data Processing:
Chunking: Efficiently breaks down large documents into manageable pieces for indexing.
Preprocessing: Handles tokenization, normalization, and embedding generation.
Integration with Vector Databases:
Default Choices: Often come pre-configured with a preferred vector database.
Similarity Algorithms: Implement standard algorithms for vector similarity search.
Simplified Configuration:
Opinionated Defaults: Provide sensible defaults for most settings, reducing the need for manual tuning.
Limited Options: Offer a curated set of configurations to prevent overwhelm.
Trieve
While many RAG Management Systems focus on general-purpose RAG deployment, Trieve specializes in search functionality. It brings thoughtful features to enhance the search experience:
Customizable Highlights: Allows developers to specify how search results are presented, including highlighted text options.
Weekly Embedding Fine-Tuning: Incorporates user feedback to improve the quality of embeddings on a regular basis.
Search Optimization: Offers typo tolerance, keyword boosting, and relevance adjustments to refine search results.
The Opinionated Nature of RAG Management Systems
These systems are inherently opinionated, meaning they come with predefined choices for critical components:
Vector Databases: Typically integrate with one or a select few databases.
Chunking Strategies: Use default methods for splitting data.
Similarity Algorithms: Implement specific algorithms for searching and ranking.
While this opinionated approach simplifies deployment and reduces configuration overhead, it also means less flexibility. Organizations must adapt to the system's choices or invest time in customizing it—if customization is even supported.
Risks of Over-Reliance on Opinionated Systems
For companies aiming to become AI-native and build fully customized RAG systems, relying heavily on an opinionated RAG Management System can pose risks:
Limited Customization:
Feature Constraints: May not support specialized features or integrations required for unique use cases.
Inflexible Architecture: Hard to modify core components without significant effort.
Vendor Lock-In:
Dependency: Tied to the system's update cycles and roadmap.
Migration Challenges: Difficult to switch to another system if the current one doesn't keep pace with technological advancements.
Rapidly Evolving Landscape:
Technological Shifts: RAG is a fast-moving field with frequent breakthroughs.
Obsolescence Risk: Systems that don't adapt quickly may become outdated, forcing companies to undertake costly migrations.
Considerations for Adoption
When deciding whether to adopt a RAG Management System, organizations should carefully assess their specific needs and long-term objectives:
Startup Speed vs. Enterprise Control:
Startups and Small Teams: For startups aiming to rapidly bring a product to market, RAG Management Systems offer a quick and efficient way to deploy RAG architectures. They handle the heavy lifting of integration and configuration, allowing teams to focus on core functionalities without delving into the complexities of underlying systems.
Large Enterprises: Enterprises often have intricate, domain-specific requirements and stringent compliance standards. They may prefer to build custom RAG systems to maintain full control over customization, security, and scalability. Developing in-house allows for tailored solutions that align precisely with organizational needs.
Alignment with Long-Term Goals:
Scalability: Does the system support your anticipated growth in data volume and user base?
Customization Needs: Can it accommodate specialized features or integrations unique to your business?
Technological Roadmap: Will the system evolve with advancements in RAG technologies, or is there a risk of it becoming obsolete?
Flexibility and Adaptability:
Configuration Options: How easily can you adjust settings or swap out components like the vector database or embedding models?
Vendor Lock-In: Are you constrained to specific tools and platforms, or does the system allow for modularity?
Community and Support:
Active Development: Is the system actively maintained with regular updates?
Support Resources: Are there forums, documentation, or customer support to assist with issues?
Ecosystem: Does it have a robust plugin or extension ecosystem to enhance functionality?
Risk Management:
Rapid Evolution of RAG: Given the fast-paced advancements in RAG, is the system agile enough to incorporate new developments?
Migration Challenges: How difficult would it be to transition away from the system if it no longer meets your needs?
Thoughts on RAG Management Systems
RAG Management Systems offer a compelling proposition, especially for startups and smaller teams seeking speed and efficiency. They abstract away much of the complexity involved in deploying RAG architectures, enabling rapid prototyping and faster time-to-market. This can be a significant advantage in competitive environments where agility is key.
However, for larger enterprises with complex needs, the trade-offs may outweigh the benefits. The opinionated nature of these systems means they come with predefined choices for critical components, which might not align with an enterprise's specific requirements. Customization limitations can impede the ability to implement specialized features, integrate with legacy systems, or adhere to strict compliance protocols.
Moreover, the RAG landscape is evolving rapidly. Relying on a rigid, opinionated system could hinder your ability to adopt new technologies or methodologies that emerge, leading to potential obsolescence. This is a significant consideration for any organization planning for long-term sustainability.
In conclusion, while RAG Management Systems can accelerate development and reduce initial overhead, it's crucial to consider the future implications. Startups may find them invaluable for gaining early traction, but as they scale, the need for greater control and customization might necessitate a shift toward more flexible solutions. Enterprises, on the other hand, might benefit more from building tailored RAG systems that offer the adaptability, security, and integration capabilities they require.
Organizations should approach the adoption of RAG Management Systems with a clear understanding of their current needs and future ambitions. By weighing the immediate benefits against potential long-term constraints, you can make an informed decision that aligns with your strategic objectives and positions you for success in the dynamic field of AI and RAG technologies.
Opportunities for Startups
The rapidly evolving RAG landscape offers a fertile ground for startups to innovate and carve out unique niches. While established players dominate certain aspects of the market, there are still ample opportunities for newcomers to make significant impacts.
Specialized Vector Databases
Despite the plethora of vector databases available, gaps remain for solutions optimized for specific use cases. Startups can seize this opportunity by developing databases tailored to niche requirements, offering competitive advantages in performance or features.
Handling Dynamic Datasets: Many existing vector databases struggle with dynamic data that require frequent updates, deletions, or real-time indexing. A startup could focus on building a vector database optimized for such dynamic datasets, ensuring low latency and high throughput even as data changes rapidly.
Specialized Data Types: Industries dealing with unique data types—like genomic sequences in biotechnology or geospatial data in logistics—need vector databases that can efficiently handle and search within these specialized datasets. Startups can create solutions that cater specifically to these needs, differentiating themselves from general-purpose databases.
Domain-Specific Infrastructure
There's a growing demand for domain-specific embedding models, vector databases, and RAG-as-a-service offerings that cater to the unique requirements of different industries.
Creating Custom Embedding Models: Startups can develop or fine-tune embedding models tailored to specific industries, enhancing retrieval relevance and accuracy.
Example: Voyage AI has begun creating domain-specific embedding models for legal, finance, and multilingual applications. They've partnered with companies like Harvey to build custom legal embeddings, addressing the specialized needs of the legal sector.
Offering RAG-as-a-Service for Specific Niches: By providing RAG solutions tailored to particular industries, startups can address unique challenges and compliance requirements.
Example: Cimulte AI offers RAG-as-a-service specifically for e-commerce, helping retailers enhance product search, recommendations, and customer experiences.
Identifying Untapped Niches
Startups should explore industries where dedicated RAG infrastructure could provide substantial value:
Healthcare: With sensitive patient data and complex medical terminology, customized RAG solutions can improve diagnostic assistance, patient record retrieval, and medical research.
Biotechnology: Handling large volumes of genomic data requires specialized vector databases and embeddings optimized for biological sequences.
Legal and Compliance: Developing RAG systems that understand legal jargon and can navigate vast libraries of legal documents can aid in case research and compliance checks.
Energy Sector: Tailored RAG solutions can help analyze geological data, optimize resource extraction, and manage infrastructure maintenance.
Education and E-Learning: Customized embeddings and retrieval systems can enhance personalized learning experiences and educational content discovery.
Leveraging Multimodal Data
Startups can innovate by focusing on multimodal RAG systems that handle text, images, audio, and other data types. This opens possibilities in fields like media, entertainment, and security, where combining different data forms can unlock new insights.
New RAG Techniques
A company that pioneers a superior RAG technique (for example, a replacement for re-ranking) can quickly gain market share.
Considerations for Enterprises
As enterprises consider integrating RAG systems into their operations, several key factors come into play.
Customization and Control
Enterprises often require solutions that can be tailored to their specific needs and integrated seamlessly with existing systems.
Data Security and Compliance: Ensuring that data remains secure and compliant with regulations is paramount. Enterprises may prefer solutions that can be deployed on-premises or within their own virtual private clouds, keeping sensitive information in-house.
Integration with Existing Infrastructure: Compatibility with current data platforms, workflows, and technology stacks is crucial to minimize disruptions and reduce implementation time.
Flexibility and Scalability: Enterprises need systems that can scale with growing data volumes and user demands while allowing for future customization as requirements evolve.
Risk Management
Adopting new technologies involves inherent risks, and enterprises must mitigate these effectively.
Avoiding Vendor Lock-In: Enterprises may be wary of being tied to a specific vendor or technology that might not adapt to future needs. Open-source solutions or platforms supporting modular components can provide more flexibility.
Future-Proofing Investments: With rapid advancements in AI and RAG technologies, enterprises need to ensure their chosen solutions will remain relevant and can incorporate new developments without requiring complete overhauls.
Operational Considerations
Resource Allocation: Implementing and maintaining RAG systems can require significant technical expertise. Enterprises must consider whether they have the necessary in-house capabilities or need to invest in training or hiring specialized personnel.
Performance and Reliability: For mission-critical applications, performance and uptime are non-negotiable. Enterprises need solutions offering robust performance guarantees and responsive support.
Balancing Speed with Control
While RAG Management Systems can accelerate development and reduce initial overhead, enterprises must weigh the immediate benefits against potential long-term constraints.
Startups and Speed: Startups may find these systems invaluable for gaining early traction, allowing them to focus on core product features and market entry.
Enterprises and Customizability: Larger organizations may prioritize control and customizability over speed. Building tailored RAG systems in-house allows for adaptability, security, and integration capabilities that align precisely with enterprise requirements.
Analysis on Market Landscape and Future Outlook
The RAG ecosystem is dynamic and rapidly evolving, with significant developments shaping the future of enterprise AI.
Convergence of Technologies
Integration of Components: There's a trend towards integrating embeddings, vector storage, and retrieval functionalities into unified platforms. This simplifies deployment and can improve performance.
Advancements in Multimodal AI: The ability to process and retrieve across different data modalities is becoming more critical, driving innovation in vector databases and embeddings that handle text, images, audio, and more.
Shifting Industry Standards
Standardization Efforts: As RAG technologies mature, we may see the emergence of common protocols and formats for vector data storage and retrieval, enhancing interoperability between systems. (LanceDB’s new data format looks pretty awesome. I hope more companies start to build around it).
Balance Between Open Source and Proprietary Solutions: Enterprises continue to weigh the benefits of open-source platforms (flexibility, control) against proprietary managed services (ease of use, support).
Conclusion
Retrieval-Augmented Generation represents a transformative shift in how organizations leverage AI to access and utilize information. Startups have ample opportunities to innovate, particularly by focusing on specialized use cases and domain-specific solutions. Enterprises, meanwhile, must carefully consider their needs for customization, control, and future-proofing as they adopt RAG technologies.
The market is poised for significant growth and change, with technological advancements continually reshaping the landscape. Organizations that stay agile and forward-thinking will be best positioned to harness the full potential of RAG, driving value and maintaining a competitive edge in their industries.
Acknowledgements
Many thanks for Morten Bruun (Co-Founder @ FlashDocs) for helping to create visuals.
Loving this post!